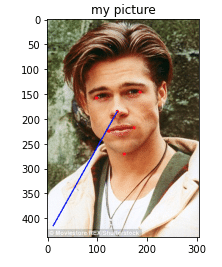
Post author:Gulliver Post published:September 7, 2020 Post category:Data science Post comments:0 Comments Recently I did some work on creating a system to identify handwritten numbers using only basic math. Below are my results Check it out on github Last updated: 07/09/2020 17:06:49 You Might Also Like Using Computer Vision to Identify Head Position August 27, 2020 Barcelona Property Market Analysis: Is the bar on the corner affecting property prices? September 13, 2020 Barcelona Property Market Analysis: Similar neighbourhoods September 14, 2020 Leave a Reply Cancel replyCommentEnter your name or username to comment Enter your email address to comment Enter your website URL (optional) Save my name, email, and website in this browser for the next time I comment. Δ
Barcelona Property Market Analysis: Is the bar on the corner affecting property prices? September 13, 2020